مفهوم اعتبارسنجی متقابل (Cross-Validation)

۱) بررسی پروسه ارزیابی مدل
ما نیاز به راهکاری داریم تا بتوانیم بین مدلهای مختلف یادگیری ماشین، یکی را انتخاب کنیم.
هدف این است که بتوانیم عملکرد مدل را برای دادههای خارج از نمونه (out-of-sample data) تخمین بزنیم.
ابتدا مجموعه دادههای iris را وارد کنید:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
حال از train/test split با مقادیر مختلف random_state استفاده میکنیم. این مقادیر، accuracy scores را تغییر میدهند.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=6)
بررسی دقت طبقهبندی KNN با K = 5:
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print(metrics.accuracy_score(y_test, y_pred))
۲) مراحل اعتبارسنجی K-fold
۱. تقسیم مجموعه دادهها به K پارتیشن (fold) برابر.
- بنابراین اگر k = 5 و مجموعه داده دارای ۱۵۰ مشاهده (observation) باشد، هر یک از ۵ فولد دارای ۳۰ مشاهده خواهند بود.
۲. از فولد ۱ به عنوان مجموعه تست، و از سایر فولدها به عنوان مجموعه آموزشی استفاده کنید.
- مجموعه تست = ۳۰ مشاهده (فولد ۱)
- مجموعه آموزش = ۱۲۰ مشاهده (فولد ۲ تا ۵)
۳. مقدار testing accuracy را محاسبه کنید.
۴. مراحل ۲ و ۳ را k مرتبه تکرار کنید و هر بار فولد متفاوتی را به عنوان مجموعه تست استفاده کنید.
- ما این پروسه را ۵ بار تکرار خواهیم کرد.
- در تکرار دوم: فولد ۲ به عنوان مجموعه تست خواهد بود و فولدهای ۱، ۳، ۴ و ۵ مجموعه آموزشی هستند.
- در تکرار سوم: فولد ۳ به عنوان مجموعه تست خواهد بود و فولدهای ۱، ۲، ۴ و ۵ مجموعه آموزشی هستند.
- و …
۵. استفاده از average testing accuracy به عنوان تخمینی از دقت دادههای خارج از نمونه (out-of-sample data)

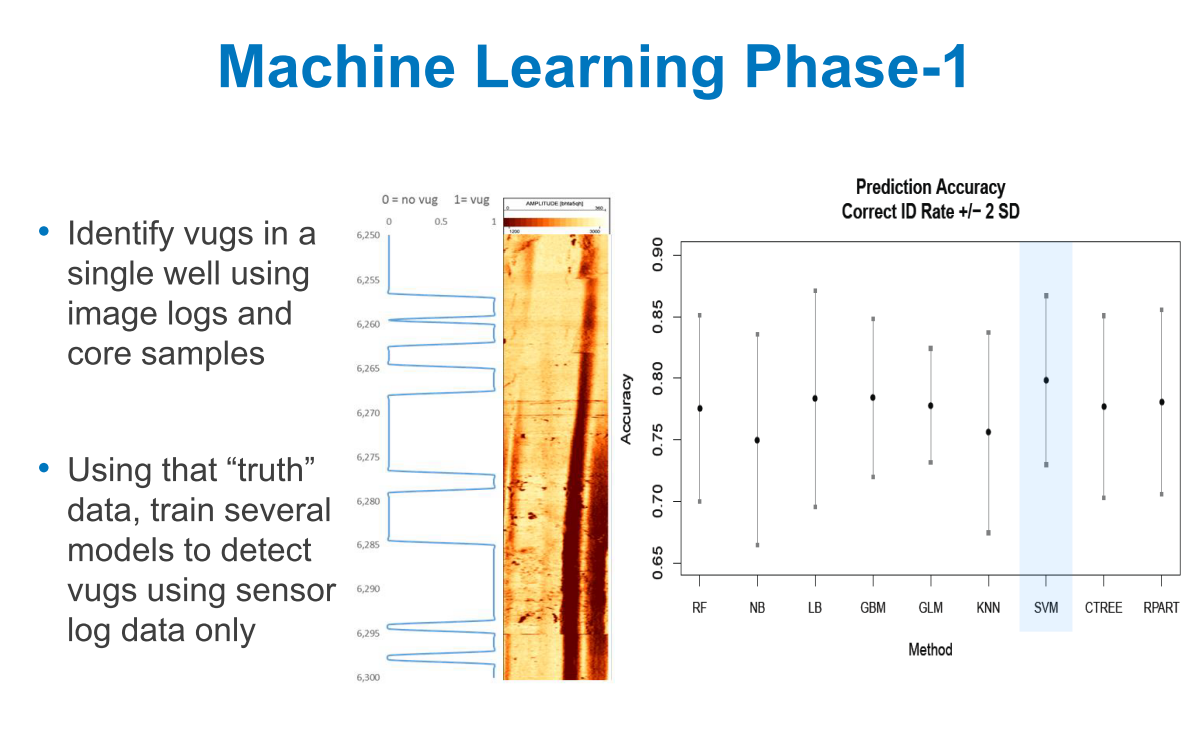
۳) مثال از اعتبار سنجی متقابل: تنظیم پارامتر (parameter tuning)
هدف: بهترین پارامترهای تنظیم را برای KNN در مجموعه داده iris انتخاب کنید.
from sklearn.cross_validation import cross_val_score
knn = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn, X, y, cv=10, scoring=’accuracy’)
print(scores)
[ ۱. ۰.۹۳۳۳۳۳۳۳ ۱. ۱. ۰.۸۶۶۶۶۶۶۷ ۰.۹۳۳۳۳۳۳۳ ۰.۹۳۳۳۳۳۳۳ ۱. ۱. ۱. ]
تعداد همسایهها برای KNN برابر با ۵ انتخاب شده است. یعنی: n_neighbors=5
تعداد فولدها برابر با ۱۰ در نظر گرفته شده است (K هر عددی میتواند باشد، اما به طور کلی K = 10 توصیه میشود). یعنی: cv=10
در تکرار اول، دقت برابر با ۱۰۰ درصد است، در تکرار دوم ۹۳ درصد و …
۷ مرحله زیر را به خاطر داشته باشید:
- تقسیم مجموعه داده (X و Y) به K = 10 پارتیشن (یا فولد) برابر
- آموزش مدل KNN بر روی تمام فولدهای ۲ تا ۱۰ (مجموعه آموزش)
- تست مدل بر روی فولد ۱ (مجموعه تست) و محاسبه دقت تست (testing accuracy)
- آموزش مدل KNN بر روی فولدهای ۱ و ۳ تا ۱۰ (مجموعه آموزش)
- تست مدل بر روی فولد ۲ (مجموعه تست) و محاسبه دقت تست (testing accuracy)
- این کار را ۸ بار دیگر انجام دهید.
- هنگامی که به پایان رسید، نمره دقت تست را برای هر ۱۰ فولد مشاهده کنید.
استفاده از دقت میانگین (average accuracy) به عنوان تخمینی از دقت دادههای خارج از نمونه (out-of-sample data)
print(scores.mean())
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring=’accuracy’)
k_scores.append(scores.mean())
print(k_scores)
[۰.۹۵۹۹۹۹۹۹۹۹۹۹۹۹۹۹۶, ۰.۹۵۳۳۳۳۳۳۳۳۳۳۳۳۳۳۷, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۵۶, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۵۶, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۷۹, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۷۹, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۷۹, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۷۹, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۷۹, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۷۹, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۸۰۰۰۰۰۰۰۰۰۰۰۰۰۰۹, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۸۰۰۰۰۰۰۰۰۰۰۰۰۰۰۹, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۸۰۰۰۰۰۰۰۰۰۰۰۰۰۰۹, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۵۶, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۵۶, ۰.۹۷۳۳۳۳۳۳۳۳۳۳۳۳۳۳۸, ۰.۹۵۹۹۹۹۹۹۹۹۹۹۹۹۹۹۶, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۵۶, ۰.۹۵۹۹۹۹۹۹۹۹۹۹۹۹۹۹۶, ۰.۹۶۶۶۶۶۶۶۶۶۶۶۶۶۶۵۶, ۰.۹۵۳۳۳۳۳۳۳۳۳۳۳۳۳۳۷, ۰.۹۵۳۳۳۳۳۳۳۳۳۳۳۳۳۳۷, ۰.۹۵۳۳۳۳۳۳۳۳۳۳۳۳۳۳۷]
print(‘Max of list’, max(k_scores))
plt.plot(k_range, k_scores)
plt.xlabel(‘Value of K for KNN’)
plt.ylabel(‘Cross-validated accuracy’)

logreg = LogisticRegression()
print(cross_val_score(logreg, X, y, cv=10, scoring=’accuracy’).mean())





دیدگاهتان را بنویسید