پیادهسازی شبکه عصبی مصنوعی با کتابخانه Scikit-Learn در پایتون
قبل از مطالعه این مطلب، حتما پست قبلی با عنوان شبکه عصبی مصنوعی چیست را مطالعه کنید (این لینک).
اکنون ما میدانیم که شبکههای عصبی مصنوعی چه هستند و چه مراحلی برای ساخت یک شبکه عصبی ساده مورد نیاز است.
در این پست سعی خواهیم کرد یک شبکه عصبی ساده ایجاد کنیم تا بتواند فرایند پیشبینی برای گیاه iris را انجام دهد.
ما از کتابخانه Scikit-Learn (کتابخانه محبوب و مهم زبان برنامهنویسی پایتون جهت اجرای کارهای هوش مصنوعی و یادگیری ماشین) برای ایجاد شبکه عصبی استفاده میکنیم تا این تمرین طبقهبندی (classification) را انجام دهیم.
مجموعه داده (Dataset)
مجموعه دادهای که ما در این آموزش استفاده میکنیم، مجموعه دادههای رایج است که در این لینک موجود است. جزئیات مجموعه دادهها در لینک فوق موجود است.
بیایید مستقیماً وارد مرحله کدنویسی شویم. اولین قدم آن است که این مجموعه داده را به برنامه وارد کنیم. برای انجام این کار از کتابخانه pandan در پایتون استفاده میکنیم.
دستور زیر را برای وارد کردن مجموعه دادههای iris به محیط پایتون اجرا کنید:
from sklearn import datasets
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Read dataset to pandas dataframe
iris = datasets.load_iris()
irisdata = pd.DataFrame(iris.data, columns= iris.feature_names)
irisdata[‘target’] = iris.target
اسکریپت بالا به سادگی دادههای iris را فراخوانی و سپس آن را در دیتافریمی (dataframe) با نام irisdata بارگذاری میکند.
برای دیدن این مجموعه داده، دستور زیر را اجرا کنید:
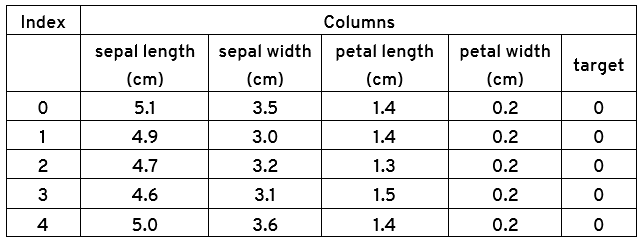
print(irisdata.head())
اجرای اسکریپت فوق پنج ردیف اول مجموعه دادههای ما را نمایش میدهد، همانطور که در زیر نشان داده شده است:

جهت مشاهده نام ویژگیها (feature) از دستور زیر استفاده کنید:
print(iris.feature_names)
نتیجه:
[‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’]
جهت مشاهده نام اهداف (target) از دستور زیر استفاده کنید:
print(iris.target_names)
نتیجه:
[‘setosa’ ‘versicolor’ ‘virginica’]
پیشپردازش دادهها (Preprocessing)
شما میتوانید ببینید که مجموعه دادهی ما دارای پنج ستون است.
حال اگر مشخصات گیاه iris جدیدی به شما داده شود و از شما خواسته شود که پیشبینی کنید که این گیاه به کدام دسته (target) متعلق است، چگونه این کار را انجام خواهید داد؟
گام بعدی این است که مجموعه دادهها را به feature ها و target ها تقسیمبندی کنیم (Splitting). برای انجام این کار از دستور زیر استفاده کنید:
# Assign data from first four columns to X variable
X = irisdata.iloc[:, 0:4]
# Assign data from first fifth columns to y variable
y = irisdata.target
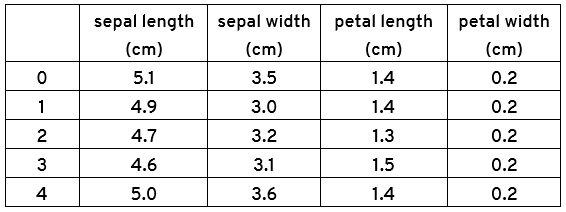
print(X.head())
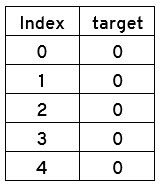
print(y.head())
نتیجه:
نکته مهم: ستون آخر که با target نمایش داده شده، گاهی اوقات label هم نامیده میشود.
Train Test Split
برای جلوگیری از over-fitting، مجموعه دادهها را به آموزش (Train) و تست (Test) تقسیم میکنیم.
دادههای آموزشی برای آموزش شبکه عصبی مورد استفاده قرار میگیرند و دادههای تست برای ارزیابی عملکرد شبکه عصبی استفاده میشوند.
برای ایجاد آموزش و تست، کد زیر را اجرا کنید:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
کد بالا، مجموعه دادههای ما رو به این صورت تقسیم میکند:
۸۰ درصد: دادههای آموزش
۲۰ درصد: دادههای تست
Feature Scaling
پیش از انجام پیشبینیهای واقعی، همیشه خوب است که feature ها را اسکیل (Scale) کنیم تا همه آنها بتوانند به طور یکسان ارزیابی شوند.
Feature Scaling تنها بر روی دادههای آموزشی و نه بر روی دادههای آزمون انجام میشود. این به این دلیل است که در دنیای واقعی، دادهها مقیاسپذیر نیستند و هدف نهایی شبکه عصبی پیشبینی دادههای واقعی جهان است. بنابراین، ما سعی میکنیم اطلاعات تست را تا حد ممکن واقعی نگه داریم.
کد زیر، عملیات Feature Scaling را انجام میدهد:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Training and Predictions
و اکنون به عنوان مرحله آخر زمان آن است که شبکه عصبی را آموزش دهیم تا بتواند پیشبینی کند.
برای انجام این کار کد زیر را اجرا کنید:
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(10, 10, 10), max_iter=1000)
mlp.fit(X_train, y_train.values.ravel())
بله، با Scikit-Learn، شما میتوانید شبکه عصبی را با این سه خط کد ایجاد کنید.
بیایید ببینیم که در کد بالا چه اتفاقی میافتد.
اولین قدم این است که کلاس MLPClassifier را از کتابخانه sklearn.neural_network وارد کنید. در خط دوم، این کلاس با دو پارامتر آغاز میشود.
پارامتر اول، hidden_layer_sizes، برای تعیین سایز لایههای مخفی استفاده میشود. در اینجا ما سه لایه را ایجاد میکنیم که هر کدام ۱۰ گره (node) دارند.
هیچ فرمول استانداردی برای انتخاب تعداد لایهها و گرهها برای یک شبکه عصبی وجود ندارد و بسته به مشکلی که در دست دارید، کاملا متفاوت است. بهترین راه این است که ترکیبهای مختلف را امتحان کنید و ببینید چه چیزی بهتر است.
پارامتر دوم در MLPClassifier تعداد تکرارها (iterations) یا دورههایی (epochs) را که میخواهید شبکه عصبی اجرا کند، تعیین میکند.
به یاد داشته باشید که یک دوره، ترکیبی از یک چرخه feed-forward و back propagation است.
به طور پیشفرض تابع فعالسازی ‘relu’ با بهینهساز هزینه ‘adam’ استفاده میشود. با این حال، میتوانید این توابع را با استفاده از پارامترهای فعالسازی و حل کننده (activation and solver parameters) تغییر دهید.
در خط سوم fit function استفاده میشود برای آموزش الگوریتم بر روی دادههای آموزشی ما یعنی X_train و y_train.
مرحله نهایی این است که پیشبینیهای مربوط به دادههای تست را انجام دهیم. برای انجام این کار کد زیر را اجرا کنید:
predictions = mlp.predict(X_test)
Evaluating the Algorithm
تا بدین جا الگوریتم خودمان را ایجاد کردیم و پیشبینیهایی را نیز بر روی مجموعه دادههای تست انجام دادیم. اکنون زمان آن فرا رسیده است تا متوجه شویم که الگوریتم ما تا چه اندازه خوب عمل میکند. برای ارزیابی الگوریتم، معیارهای معمول استفاده شده عبارتند از:
- confusion matrix
- precision
- recall
- f1 score
روشهای confusion_matrix و classification_report کتابخانه sklearn.metrics میتوانند به ما در پیدا کردن این نمرات کمک کنند. کد زیر گزارش ارزیابی الگوریتم ما را تولید میکند:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test,predictions))
print(classification_report(y_test,predictions))
این کد نتیجه زیر را تولید میکند:
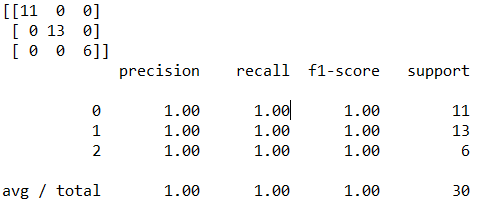
تفسیر گزارش بالا:
در ابتدا یک ماتریش سه در سه مشاهده میشود که اعدادِ روی قطر اصلی آن به ترتیب ۱۱، ۱۳ و ۶ هستند. این بدان معناست که از ۳۰ دادهای که برای تست شبکه استفاده شد، ۱۱ داده متعلق به کلاس Setosa هستند، ۱۳ داده متعلق به کلاس Versicolor و ۶ داده نیر متعلق به کلاس Virginica میباشند. این دادهها در واقعیت متعلق به این کلاسها بودهاند و توسط شبکه نیز به درستی تشخیص داده شدهاند.
مقدار f1-score برابر ۱ است که نتیجه بسیار خوبی میباشد. هر چقدر f1 به عدد یک نزدیکتر باشد، شبکه بهتری داریم.
تذکر مهم: نتایج شما میتواند کمی از اینها متفاوت باشد؛ زیرا train_test_split به طور تصادفی دادهها را به مجموعههای آموزشی و تست تقسیم میکند. بنابراین ممکن است شما با اجرای مجدد شبکه، نتایج متفاوتی دریافت کنید. اما به طور کلی، دقت (accuracy ) باید بیش از ۹۰ درصد باشد.
در پست بعدی توضیحات بیشتری در مورد Confusion Matrix خدمت شما ارائه خواهد شد.





دیدگاهتان را بنویسید