

کاربرد یادگیری ماشین برای پیشبینی دبی نفت در چاههای تحت فرازآوری مصنوعی با گاز

در این پست قصد دارم یک مقاله ۲۰۱۹ وان پترو را که در مورد کاربرد یادگیری ماشین در حوزه مهندسی بهرهبرداری است بررسی کنم.
دبی تولیدی چاه یکی از مهمترین پارامترها برای ارزیابی عملکرد سیستم تولیدی میباشد.
در صنعت، جهت محاسبه دبی تولیدی یک چاه از روابط و فرمولها استفاده میکنند. ولی به مرور زمان متوجه شدهاند که استفاده از این روابط به دلیل برخی مسائل تکنیکی و اقتصادی موثر نیست.
حال در این پست قصد داریم با استفاده از الگوریتمهای یادگیری ماشین یک رابطه برای پیشبینی دقیق دبی نفت در چاههای تحت فرازآوری مصنوعی با گاز استفاده کنیم. این الگوریتمها عبارتند از:
- Artificial Neuro Fuzzy Inference Systems یا همان ANFIS
- Support Vector Machines یا همان SVM
- Artificial Neural Network یا همان ANN
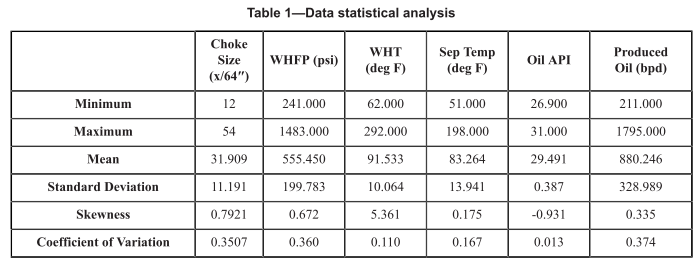
دیتاست ما شامل ۱۹۵۰ داده تست تفکیکگر (separator test) میباشد که بعد از فرایند پاکسازی دادهها (data cleaning) به منظور حذف دادههای دارای خطا، به مقدار ۱۵۰۰ داده تقلیل پیدا کرد.
صرفا پارامترهای سرچاهی به عنوان ورودی مدل استفاده شدهاند.
نکته مهم این است که مدل ارائه شده باید کاربرد جهانی داشته باشد و در همه میادین و چاهها قابل استفاده باشد.
گیلبرت (Gilbert) یکی از مهمترین روابط محاسبه دبی نفت (دبی جریانی عبوری از چوک) را پیشنهاد کرده است:

تمام محققانی که بعد از گیلبرت یک سری روابط پیشنهاد دادند، همه آنها حول و هوش همین معادله گیلبرت بوده است و این در حالی است که خودِ رابطه گیلبرت نیز دارای محدودیت در کاربرد میباشد.
دیتاست اولیه شامل ۱۴ ویژگی (feature) میباشد:
- سایز چوک
- دمای بالادستی و پایین دستی چوک
- فشار بالادستی و پایین دستی چوک
- دبی آب و گاز و نفت
- نسبت گاز به مایع
- فشار تزریق گاز در فرایند فرازآوری با گاز
- API
- وزن مخصوص گاز
- پارامترهای دیگری همچون مقدار گاز دی اکسید کرین و سولفید هیدروژن، pH ومقدار کلوراید
به دلیل انجام فرایند “استخراج ویژگی” تعدادی پارامترهای ورودی مدل از ۱۴ به ۴ پارامتر کاهش یافت:
- سایز چوک (Choke size)
- فشار بالادستی (WHFP)
- دمای بالادستی (WHT) و پایین دستی (Sep Temp)
- API
خروجی مدل نیز دبی نفت اندازهگیری شده در تفکیکگر میباشد.
۷۰ درصد دادهها برای آموزش و ۳۰ درصد برای تست الگوریتم استفاده شده است.
ANN
یکی از کارهای بسیار مهمی که باید انجام دهیم، یافتن مقادیر بهینه پارامترهایی همچون تعداد نورونها، تعداد لایهها، تابع انتقال و … در الگوریتم شبکه عصبی مصنوعی میباشد. برای این کار باید آنالیز حساسیت بر روی این پارامترها انجام دهیم. شبکه عصبی مصنوعی طراحی شده شامل موارد زیر است:
- ۳ لایه (لایه ورودی، لایه خروجی و لایه پنهان)
- یک لایه پنهان با ۶ نورون
- الگوریتم یادگیری، trainlm میباشد.
- تابع انتقال، logsig میباشد.
ANFIS
برای تعیین تعداد ورودیهای مدل، از روش خوشهبندی کاهشی (subtractive clustering) استفاده میکنیم. برای این کار باید مقادیر دو پارامتر را بهینه کنیم:
- cluster radius
- number of epoches
تعداد epoch به ۴۰۰ عدد محدود شد؛ زیرا با افزایش تعداد epoch ها به بیشتر از این مقدار، زمان محاسبات افزایش ولی نتایج تغییری نکرد.
SVM
در این الگوریتم باید مقادیر ۶ پارامتر بهینه شوند تا بهترین نتیجه را بگیریم:
- lambda
- epsilon
- kernel-option
- verbose
- C
- kernel
مشاهده گردید که tune کردن پارامترهای lambda و epsilon و verbose تاثیر زیادی بر روی خروجی نداشت، بنابراین آنالیز حساسیت بر روی سایر پارامترها انجام شد.
رابطه تجربی برای محسابه دبی نفت با استفاده از ANN

مراحل استفاده از این رابطه تجربی:
۱- نرمالسازی دادههای ورودی (Input Data Normalization): برای این کار از رابطه زیر استفاده میکنیم:

۲- محاسبه Qoiln
۳- دی نرمالسازی دادهها (De-normalization): مقدار دبی بر حسب بشکه در روز به صورت زیر میباشد:
![]()
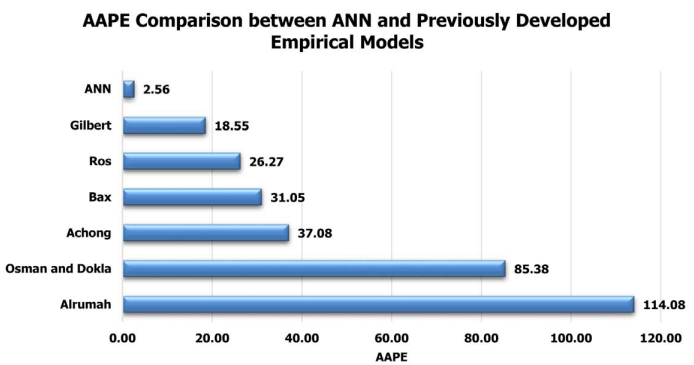
در این پروژه، بهترین مدل ANN است (R2=0.99 و AAPE=2.56%).
در گام بعدی باید یک زیرمجموعه از دادهها را که تا کنون استفاده نکردهایم، برای مقایسه نتایج مدل ANN با سایر روابط تجربی به کار ببریم.
دوره آموزشی روشهای فرازآوری مصنوعی در ایران (گس لیفت، پمپ ESP و پمپ SRP)











